Hướng Dẫn Chuyển Tiếng Việt Có Dấu Sang Không Dấu Bằng C#

Trong nhiều ứng dụng thực tế, việc chuyển đổi văn bản tiếng Việt có dấu sang dạng không dấu là một yêu cầu phổ biến. Điều này đặc biệt hữu ích khi xử lý tên tệp, tạo URL thân thiện với công cụ tìm kiếm (SEO), hoặc lưu trữ dữ liệu trong các hệ thống không hỗ trợ ký tự Unicode phức tạp. Bài viết này sẽ cung cấp các phương pháp hiệu quả và chi tiết để thực hiện chuyển đổi này bằng ngôn ngữ lập trình C#, kèm theo các ví dụ minh họa cụ thể.

Đề Bài
Bài viết gốc cung cấp các đoạn mã C# để chuyển đổi văn bản tiếng Việt có dấu sang dạng không dấu. Mục tiêu là xử lý các ký tự có dấu (như á, à, ả, ã, ạ, ă, ắ, ằ,ẳ, ẵ, ặ, â, ấ, ầ, ẩ, ẫ, ậ, đ, é, è, ẻ, ẽ, ẹ, ê, ế, ề, ể, ễ, ệ, v.v.) thành các ký tự tương ứng không dấu (a, d, e, v.v.).
[
Phân Tích Yêu Cầu
Yêu cầu cốt lõi là tạo ra một hàm hoặc một chuỗi các thao tác trong C# có khả năng nhận vào một chuỗi ký tự tiếng Việt và trả về một chuỗi mới đã loại bỏ hoàn toàn các dấu thanh và dấu mũ, đồng thời giữ nguyên các phụ âm và nguyên âm cơ bản. Cụ thể, các nguyên âm có dấu như ‘á’, ‘à’, ‘ả’, ‘ã’, ‘ạ’ cần được chuyển thành ‘a’; ‘é’, ‘è’, ‘ẻ’, ‘ẽ’, ‘ẹ’ thành ‘e’; ‘í’, ‘ì’, ‘ỉ’, ‘ĩ’, ‘ị’ thành ‘i’; ‘ó’, ‘ò’, ‘ỏ’, ‘õ’, ‘ọ’ thành ‘o’; ‘ú’, ‘ù’, ‘ủ’, ‘ũ’, ‘ụ’ thành ‘u’; ‘ý’, ‘ỳ’, ‘ỷ’, ‘ỹ’, ‘ỵ’ thành ‘y’. Đặc biệt, ký tự ‘đ’ cần được chuyển thành ‘d’ và ‘Đ’ thành ‘D’.
Kiến Thức/Nền Tảng Cần Dùng
Để thực hiện việc chuyển đổi này, chúng ta cần hiểu về cấu trúc của bảng chữ cái tiếng Việt và cách các ký tự có dấu được biểu diễn. Tiếng Việt sử dụng bảng chữ cái Latinh với các dấu phụ (diacritics) để biểu thị thanh điệu và nguyên âm khác nhau.
1. Sơ lược về bảng chữ cái tiếng Việt
Bảng chữ cái tiếng Việt bao gồm 29 chữ cái: a, ă, â, b, c, d, đ, e, ê, g, h, i, k, l, m, n, o, ô, ơ, p, q, r, s, t, u, ư, v, x, y. Bên cạnh đó là các dấu thanh: sắc (´), huyền (`), hỏi (?), ngã (~), nặng (.). Các nguyên âm như ‘a’ có thể kết hợp với các dấu mũ (ă, â) hoặc dấu thanh để tạo thành các âm tiết khác nhau.
[
Khi chuyển đổi sang không dấu, ý tưởng cơ bản là thay thế mỗi ký tự có dấu bằng ký tự gốc không có dấu. Ví dụ: ‘á’, ‘à’, ‘ả’, ‘ã’, ‘ạ’ đều được thay thế bằng ‘a’; ‘ắ’, ‘ằ’, ‘ẳ’, ‘ẵ’, ‘ặ’ thành ‘ă’ (hoặc có thể quy về ‘a’ tùy theo yêu cầu cụ thể); ‘ấ’, ‘ầ’, ‘ẩ’, ‘ẫ’, ‘ậ’ thành ‘â’ (hoặc quy về ‘a’). Ký tự ‘đ’ là một trường hợp đặc biệt, nó không phải là ‘d’ có dấu huyền mà là một chữ cái riêng biệt trong bảng chữ cái tiếng Việt.
2. Chuẩn hóa Unicode (Normalization)
Trong .NET Framework, lớp System.String cung cấp phương thức Normalize với các dạng chuẩn hóa khác nhau. NormalizationForm.FormD (Canonical Decomposition) là dạng chuẩn hóa hữu ích trong trường hợp này. Nó phân tách các ký tự có dấu thành ký tự gốc và một ký tự “dấu phụ” riêng biệt. Ví dụ, ký tự ‘á’ (U+00E1) sẽ được phân tách thành ‘a’ (U+0061) và dấu sắc (U+0301). Sau khi phân tách, chúng ta có thể dễ dàng loại bỏ các ký tự dấu phụ này.
3. Biểu thức chính quy (Regular Expressions)
Biểu thức chính quy là một công cụ mạnh mẽ để tìm kiếm và thay thế các mẫu ký tự trong chuỗi. Chúng ta có thể sử dụng Regex để định nghĩa các mẫu ký tự có dấu và thay thế chúng bằng các ký tự không dấu tương ứng, hoặc để tìm và loại bỏ các ký tự dấu phụ sau khi đã chuẩn hóa chuỗi.
4. Lớp StringBuilder
Khi thực hiện nhiều thao tác thay thế trên một chuỗi, việc sử dụng StringBuilder sẽ hiệu quả hơn so với việc liên tục tạo ra các đối tượng String mới. StringBuilder cho phép sửa đổi chuỗi một cách hiệu quả trong bộ nhớ.
Hướng Dẫn Giải Chi Tiết
Dựa trên các kiến thức nền tảng, chúng ta có thể xây dựng nhiều cách tiếp cận khác nhau để giải quyết bài toán này. Dưới đây là ba cách tiếp cận được trình bày trong bài viết gốc, từ cách thủ công đến các cách sử dụng tính năng chuẩn hóa của .NET.
Cách thứ nhất: Sử dụng biểu thức chính quy và mảng thay thế thủ công
Cách này dựa trên việc định nghĩa rõ ràng từng nhóm ký tự có dấu và ánh xạ chúng tới ký tự không dấu tương ứng.
- Ý tưởng: Tạo ra các mẫu biểu thức chính quy cho từng nhóm nguyên âm có dấu (ví dụ:
(á|à|ả|ã|ạ|ă|ắ|ằ|ẳ|ẵ|ặ|â|ấ|ầ|ẩ|ẫ|ậ)cho nguyên âm ‘a’). Sau đó, lặp qua các mẫu này, tìm các ký tự khớp và thay thế chúng bằng ký tự không dấu tương ứng. - Triển khai:
- Khai báo một mảng các chuỗi
patternchứa các biểu thức chính quy cho từng nhóm nguyên âm. - Khai báo một mảng ký tự
replaceCharchứa các ký tự không dấu tương ứng. Cần lưu ý đến việc xử lý cả chữ hoa và chữ thường. - Sử dụng
Regex.Matchesđể tìm tất cả các lần xuất hiện của mẫu trong chuỗi đầu vào. - Với mỗi lần khớp, xác định xem ký tự gốc là chữ hoa hay chữ thường và thay thế bằng ký tự không dấu tương ứng từ mảng
replaceChar. - Lưu ý: Đoạn mã này sử dụng
unsafe staticvà con trỏ (fixed (char ptrChar = replaceChar)). Để biên dịch mã này, bạn cần bật tùy chọn “Allow unsafe code” trong thuộc tính dự án C#.
- Khai báo một mảng các chuỗi
using System.Text.RegularExpressions;
public unsafe static string converToUnsign1(string s)
{
string[] pattern = {
"(á|à|ả|ã|ạ|ă|ắ|ằ|ẳ|ẵ|ặ|â|ấ|ầ|ẩ|ẫ|ậ)", // a
"đ", // d
"(é|è|ẻ|ẽ|ẹ|ê|ế|ề|ể|ễ|ệ)", // e
"(í|ì|ỉ|ĩ|ị)", // i
"(ó|ò|ỏ|õ|ọ|ô|ố|ồ|ổ|ỗ|ộ|ơ|ớ|ờ|ở|ỡ|ợ)", // o
"(ú|ù|ủ|ũ|ụ|ư|ứ|ừ|ử|ữ|ự)", // u
"(ý|ỳ|ỷ|ỹ|ỵ)" // y
};
char[] replaceChar = {
'a', 'd', 'e', 'i', 'o', 'u', 'y', // Chữ thường
'A', 'D', 'E', 'I', 'O', 'U', 'Y' // Chữ hoa (cần thêm 7 ký tự cho chữ hoa tương ứng)
};
fixed (char ptrChar = replaceChar)
{
for (int i = 0; i < pattern.Length; i++)
{
MatchCollection matchs = Regex.Matches(s, pattern[i], RegexOptions.IgnoreCase);
foreach (Match m in matchs)
{
// Xác định ký tự thay thế dựa trên chữ hoa/thường
char replacement = char.IsLower(m.Value[0]) ? (ptrChar + i) : (ptrChar + i + 7);
s = s.Replace(m.Value[0], replacement);
}
}
}
return s;
}- Mẹo kiểm tra: Sau khi chạy hàm, kiểm tra các chuỗi có chứa các ký tự có dấu ban đầu để xem chúng đã được thay thế chính xác chưa. Ví dụ: “Tiếng Việt có dấu” phải thành “Tieng Viet co dau”.
- Lỗi hay gặp: Quên bật “Allow unsafe code”, xử lý sai chữ hoa/thường, thiếu các trường hợp nguyên âm kép hoặc các tổ hợp dấu mũ/thanh phức tạp.
Cách thứ hai: Sử dụng chuẩn hóa Unicode FormD và StringBuilder
Cách này tận dụng khả năng chuẩn hóa của .NET để tách dấu phụ ra khỏi nguyên âm, sau đó loại bỏ chúng.
- Ý tưởng: Chuẩn hóa chuỗi về dạng
NormalizationForm.FormDđể tách các ký tự có dấu thành ký tự gốc và ký tự dấu phụ. Sau đó, duyệt qua chuỗi đã chuẩn hóa, chỉ giữ lại các ký tự không phải là dấu phụ. Cuối cùng, xử lý riêng ký tự ‘đ’ và ‘Đ’. - Triển khai:
- Sử dụng
s.Normalize(NormalizationForm.FormD)để phân tách chuỗi. - Khởi tạo một
StringBuilder. - Duyệt qua từng ký tự trong chuỗi đã chuẩn hóa. Sử dụng
CharUnicodeInfo.GetUnicodeCategoryđể xác định xem ký tự đó có thuộc loại “NonSpacingMark” (dấu phụ) hay không. Nếu không phải dấu phụ, thêm ký tự đó vàoStringBuilder. - Sau khi duyệt xong, thực hiện thay thế
sb.Replace('Đ', 'D')vàsb.Replace('đ', 'd'). - Cuối cùng, gọi
sb.ToString().Normalize(NormalizationForm.FormD)một lần nữa để đảm bảo chuỗi kết quả được chuẩn hóa đúng cách (mặc dù bước này có thể không cần thiết nếu các ký tự ‘đ’/’Đ’ đã được xử lý đúng).
- Sử dụng
[
using System.Text;
using System.Globalization;
public string convertToUnSign2(string s)
{
// Chuẩn hóa về dạng phân tách (ví dụ: 'á' thành 'a' + dấu sắc)
string stFormD = s.Normalize(NormalizationForm.FormD);
StringBuilder sb = new StringBuilder();
for (int ich = 0; ich < stFormD.Length; ich++)
{
// Lấy loại Unicode của ký tự
UnicodeCategory uc = CharUnicodeInfo.GetUnicodeCategory(stFormD[ich]);
// Nếu không phải là NonSpacingMark (dấu phụ), thì giữ lại
if (uc != UnicodeCategory.NonSpacingMark)
{
sb.Append(stFormD[ich]);
}
}
// Xử lý riêng ký tự 'đ' và 'Đ'
sb.Replace('Đ', 'D');
sb.Replace('đ', 'd');
// Chuẩn hóa lại lần cuối (có thể không cần thiết tùy trường hợp)
return (sb.ToString().Normalize(NormalizationForm.FormD));
}- Mẹo kiểm tra: Kiểm tra các ký tự dấu mũ như ‘â’, ‘ê’, ‘ô’, ‘ơ’, ‘ư’ xem chúng có bị mất đi không. Cách này thường giữ lại các nguyên âm có dấu mũ (ă, â, ê, ô, ơ, ư) nhưng loại bỏ các dấu thanh. Nếu yêu cầu là quy hết về nguyên âm cơ bản (a, e, i, o, u, y), cần thêm bước xử lý sau khi loại bỏ dấu phụ.
- Lỗi hay gặp: Không xử lý đúng ký tự ‘đ’/’Đ’, hoặc không hiểu rõ về các loại Unicode Category, dẫn đến việc loại bỏ nhầm các ký tự không phải dấu phụ.
Cách thứ ba: Sử dụng Regex và chuẩn hóa Unicode ngắn gọn
Cách này tương tự cách thứ hai nhưng sử dụng biểu thức chính quy để loại bỏ các dấu phụ, làm cho mã nguồn ngắn gọn hơn.
- Ý tưởng: Kết hợp chuẩn hóa Unicode FormD với biểu thức chính quy để tìm và loại bỏ các ký tự dấu phụ.
- Triển khai:
- Chuẩn hóa chuỗi về dạng
NormalizationForm.FormD. - Sử dụng
Regexvới mẫup{IsCombiningDiacriticalMarks}+để tìm tất cả các ký tự dấu phụ liên tiếp. - Thay thế các ký tự dấu phụ tìm được bằng chuỗi rỗng (
String.Empty). - Cuối cùng, thay thế ‘đ’ bằng ‘d’ và ‘Đ’ bằng ‘D’.
- Chuẩn hóa chuỗi về dạng
using System.Text.RegularExpressions;
public static string convertToUnSign3(string s)
{
// Mẫu Regex để tìm các ký tự dấu phụ (combining diacritical marks)
Regex regex = new Regex(@"p{IsCombiningDiacriticalMarks}+");
// Chuẩn hóa về dạng phân tách
string temp = s.Normalize(NormalizationForm.FormD);
// Loại bỏ các dấu phụ và thay thế 'đ'/'Đ'
return regex.Replace(temp, String.Empty)
.Replace('đ', 'd')
.Replace('Đ', 'D');
}- Mẹo kiểm tra: Cách này cho kết quả tương tự cách thứ hai. Kiểm tra xem các dấu thanh và dấu mũ có được xử lý đúng như mong đợi hay không.
- Lỗi hay gặp: Mẫu Regex có thể chưa bao quát hết tất cả các loại dấu phụ nếu bảng mã Unicode mở rộng. Tuy nhiên, với các ký tự tiếng Việt thông thường, mẫu này thường hoạt động tốt.
5. Chương trình Demo chuyển tiếng Việt có dấu sang không dấu với C
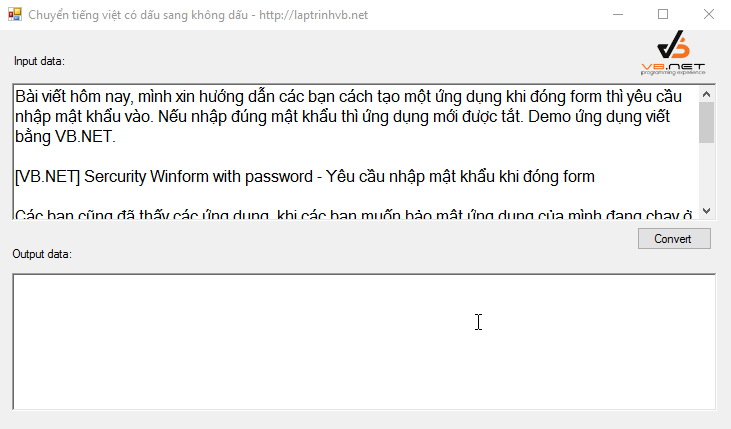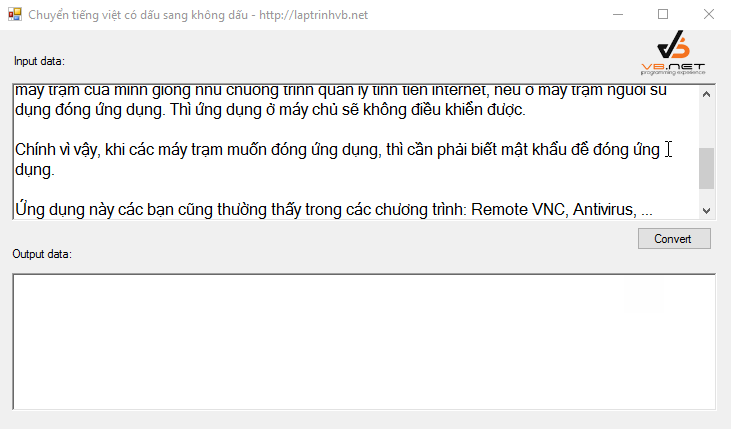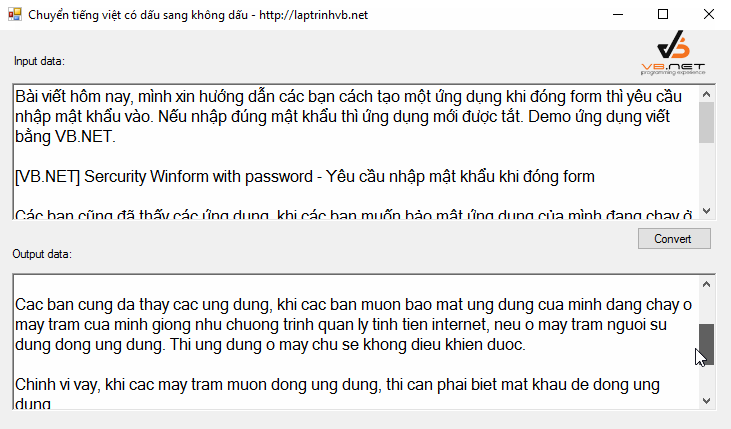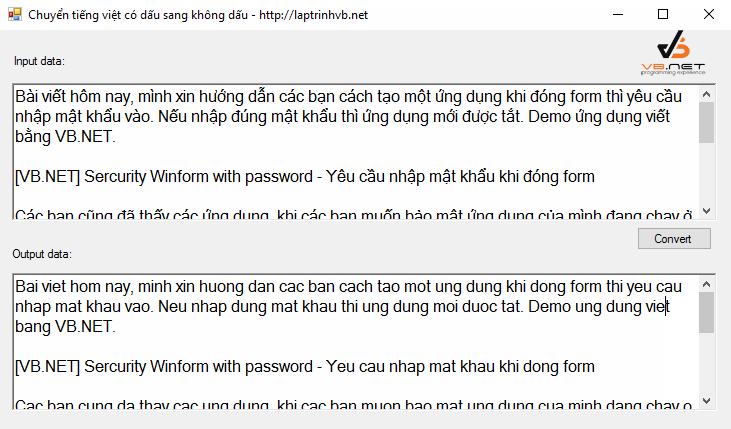
Để minh họa cho các phương pháp trên, một ứng dụng demo đã được xây dựng trên Visual Studio 2010 sử dụng C#. Ứng dụng này có giao diện đơn giản với hai ô nhập liệu. Khi người dùng nhập văn bản có dấu vào ô trên, ô dưới sẽ tự động hiển thị kết quả đã chuyển đổi sang không dấu theo thời gian thực (sự kiện TextChanged).
[
Chương trình demo này tích hợp cả ba cách đã trình bày, cho phép người dùng so sánh và lựa chọn phương pháp phù hợp nhất với nhu cầu của mình. Mã nguồn chi tiết của ứng dụng demo có thể được tải về để tham khảo và tùy chỉnh thêm.
- Link tải mã nguồn: Click vào đây để download source code chương trình demo chuyển đổi tiếng Việt có dấu sang không dấu viết trên C# (Lưu ý: Liên kết này có thể không còn hoạt động do thời gian).
Đáp Án/Kết Quả
Các phương pháp trên đều cung cấp giải pháp hiệu quả để chuyển đổi văn bản tiếng Việt có dấu sang không dấu trong C#.
- Cách 1: Phù hợp khi bạn muốn kiểm soát hoàn toàn quá trình thay thế và có thể cần xử lý các trường hợp đặc biệt không theo quy tắc chuẩn hóa Unicode. Tuy nhiên, mã nguồn dài dòng và yêu cầu bật
unsafe code. - Cách 2 & 3: Là những phương pháp hiện đại và hiệu quả hơn, tận dụng các tính năng có sẵn của .NET Framework. Cách 3, sử dụng Regex, thường được ưa chuộng vì tính ngắn gọn và dễ đọc hơn.
Kết quả cuối cùng là một chuỗi ký tự ASCII, loại bỏ các dấu thanh và dấu mũ, đồng thời chuyển đổi ‘đ’ thành ‘d’, giúp văn bản tương thích tốt hơn với nhiều hệ thống và ứng dụng.
Kết luận
Việc chuyển đổi tiếng Việt có dấu sang không dấu là một kỹ năng lập trình hữu ích, đặc biệt khi làm việc với các ứng dụng web hoặc hệ thống yêu cầu định dạng văn bản chuẩn hóa. Bằng cách áp dụng các phương pháp sử dụng chuẩn hóa Unicode và biểu thức chính quy trong C#, bạn có thể dễ dàng thực hiện tác vụ này một cách hiệu quả và chính xác, đảm bảo tính tương thích và khả năng xử lý dữ liệu tốt hơn.
Ngày chỉnh sửa nội dung mới nhất January 14, 2026 by Thầy Đông

Thầy Đông – Giảng viên Đại học Công nghiệp Hà Nội, giáo viên luyện thi THPT
Thầy Đông bắt đầu sự nghiệp tại một trường THPT ở quê nhà, sau đó trúng tuyển giảng viên Đại học Công nghiệp Hà Nội nhờ chuyên môn vững và kinh nghiệm giảng dạy thực tế. Với nhiều năm đồng hành cùng học sinh, thầy được biết đến bởi phong cách giảng dạy rõ ràng, dễ hiểu và gần gũi. Hiện thầy giảng dạy tại dehocsinhgioi, tiếp tục truyền cảm hứng học tập cho học sinh cấp 3 thông qua các bài giảng súc tích, thực tiễn và giàu nhiệt huyết.












